Abstract
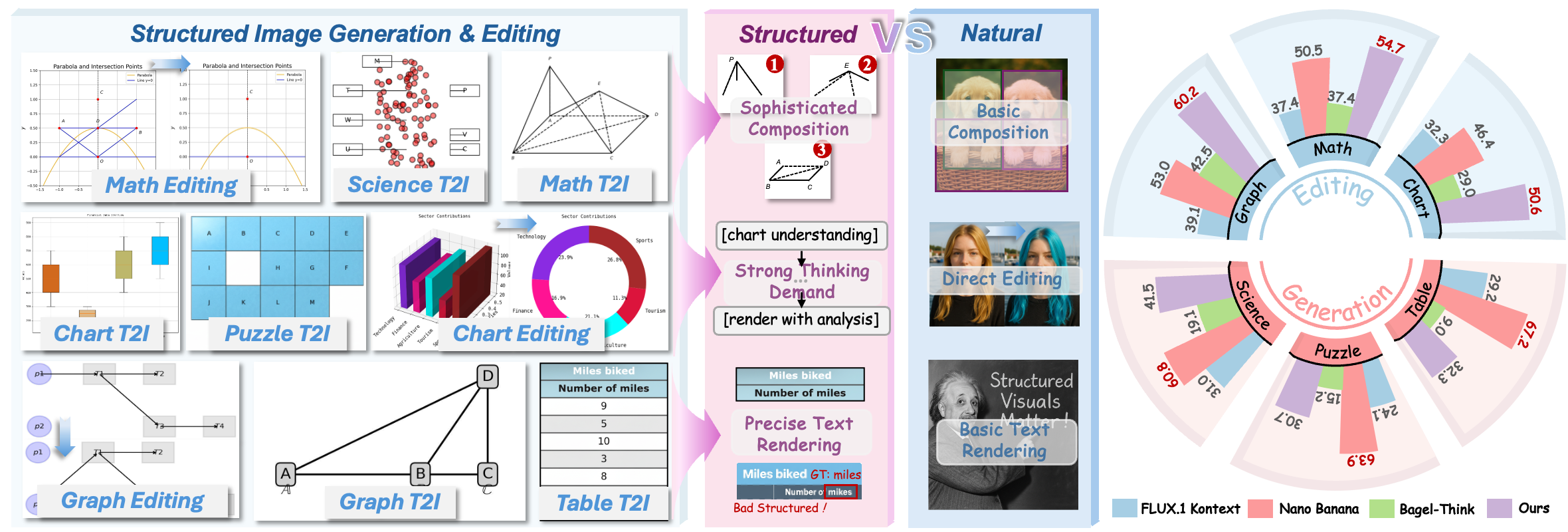
While modern visual generation models excel at creating aesthetically pleasing natural images, they struggle with producing or editing structured visuals like charts, diagrams, and mathematical figures, which demand composition planning, text rendering, and multimodal reasoning for factual fidelity. To address this, we present the first comprehensive, systematic investigation of this domain, encompassing data construction, model training, and an evaluation benchmark. First, we construct a large-scale dataset of 1.3 million high-quality structured image pairs derived from executable drawing programs and augmented with chain-of-thought reasoning annotations. Building on it, we train a unified model that integrates a VLM with FLUX.1 Kontext via a lightweight connector for enhanced multimodal understanding. A three-stage training curriculum enables progressive feature alignment, knowledge infusion, and reasoning-augmented generation, further boosted by an external reasoner at inference time. Finally, we introduce StructBench, a novel benchmark for generation and editing with over 1,700 challenging instances, and an accompanying evaluation metric, StructScore, which employs a multi-round Q\&A protocol to assess fine-grained factual accuracy. Evaluations of 15 models reveal that even leading closed-source systems remain far from satisfactory. Our model attains strong editing performance, and inference-time reasoning yields consistent gains across diverse architectures. By releasing the dataset, model, and benchmark, we aim to advance unified multimodal foundations for structured visuals.
StructBench Leaderboard
🎯 Welcome to StructBench! We invite you to evaluate your model and submit your results to the leaderboard!
Please report Accuracy (%) and PSNR for StructEditBench, and Accuracy (%) for StructT2IBench with each submission.
📧 Contact us at zhuole1025@gmail.com or hshjerry@buaa.edu.cn to submit your results.
StructEditBench — reporting Accuracy (%) & PSNR. Click any column to sort. Best Performance Second Best
| Model | Math | Chart | Graph | Puzzle | Science | Table | Overall | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc ↑ | PSNR ↑ | Acc ↑ | PSNR ↑ | Acc ↑ | PSNR ↑ | Acc ↑ | PSNR ↑ | Acc ↑ | PSNR ↑ | Acc ↑ | PSNR ↑ | Acc ↑ | PSNR ↑ | |
| Nano Banana | 50.46 | 20.77 | 46.42 | 14.93 | 52.97 | 21.22 | 66.56 | 22.92 | 69.16 | 22.61 | 75.71 | 19.75 | 51.57 | 21.09 |
| GPT-Image | 51.49 | 17.06 | 45.82 | 12.56 | 50.71 | 17.24 | 76.03 | 16.55 | 67.61 | 16.61 | 83.26 | 14.35 | 52.20 | 16.64 |
| Seedream 4.0 | 51.06 | 23.63 | 46.83 | 16.54 | 51.72 | 24.12 | 71.13 | 26.93 | 69.22 | 26.46 | 88.19 | 24.75 | 52.85 | 24.45 |
| UniWorld-V1 | 9.41 | 8.84 | 5.99 | 7.87 | 8.83 | 6.16 | 9.11 | 7.71 | 19.91 | 7.67 | 16.13 | 8.24 | 8.40 | 8.21 |
| DiMOO | 26.79 | 21.56 | 16.52 | 14.98 | 24.03 | 21.77 | 29.52 | 22.26 | 26.08 | 22.57 | 24.64 | 19.47 | 21.00 | 21.49 |
| OmniGen2 | 29.44 | 15.95 | 18.55 | 12.44 | 34.63 | 11.31 | 28.61 | 16.51 | 39.55 | 15.60 | 30.36 | 16.60 | 24.30 | 15.49 |
| Ovis-U1 | 31.64 | 18.45 | 21.94 | 13.30 | 38.03 | 19.01 | 42.08 | 17.92 | 44.52 | 18.68 | 35.58 | 16.62 | 28.06 | 18.25 |
| Hidream-E1.1 | 28.07 | 18.43 | 26.36 | 12.91 | 29.63 | 18.26 | 43.77 | 18.04 | 36.66 | 16.47 | 48.79 | 17.12 | 29.63 | 18.01 |
| Bagel | 21.27 | 21.38 | 27.11 | 16.38 | 29.94 | 22.70 | 41.59 | 24.22 | 47.16 | 23.56 | 47.35 | 21.54 | 28.87 | 22.06 |
| Bagel-Think | 37.40 | 23.97 | 28.98 | 16.82 | 42.51 | 26.49 | 36.11 | 26.75 | 43.15 | 25.57 | 40.46 | 23.83 | 33.34 | 24.70 |
| Step1X-Edit | 34.47 | 23.41 | 28.05 | 16.68 | 33.26 | 24.56 | 60.48 | 25.94 | 46.47 | 24.98 | 57.81 | 23.97 | 34.11 | 24.03 |
| FLUX.1 Kontext | 37.36 | 19.78 | 32.29 | 14.61 | 39.12 | 20.10 | 58.35 | 20.38 | 50.39 | 20.99 | 58.05 | 18.52 | 37.56 | 19.84 |
| Qwen-Edit | 40.48 | 23.73 | 30.17 | 12.33 | 44.83 | 26.11 | 53.74 | 27.31 | 55.99 | 25.53 | 67.76 | 25.71 | 38.12 | 24.81 |
| Ours | 54.74 | 23.31 | 50.58 | 15.33 | 60.18 | 24.65 | 73.00 | 26.33 | 75.05 | 25.80 | 77.08 | 23.19 | 55.98 | 24.01 |
Quantitative comparison on StructT2IBench, reporting Accuracy (%). Each column is clickable to view its ranking. Best Performance Second Best
| Model | Chart | Graph | Math | Puzzle | Science | Table | Overall |
|---|---|---|---|---|---|---|---|
| Acc ↑ | Acc ↑ | Acc ↑ | Acc ↑ | Acc ↑ | Acc ↑ | Acc ↑ | |
| Seedream 4.0 | 35.79 | 54.08 | 63.33 | 50.89 | 62.59 | 68.94 | 47.52 |
| Nano banana | 35.55 | 58.96 | 64.81 | 63.87 | 60.75 | 67.20 | 48.45 |
| GPT-Image | 37.09 | 57.00 | 63.25 | 59.42 | 60.94 | 83.31 | 49.58 |
| UniWorld-V1 | 1.71 | 5.52 | 4.72 | 1.58 | 8.82 | 5.25 | 3.20 |
| Bagel | 4.66 | 3.61 | 4.02 | 4.46 | 8.60 | 5.74 | 4.69 |
| Bagel-Think | 4.81 | 15.33 | 13.89 | 15.22 | 19.05 | 8.97 | 9.03 |
| Hidream-I1-Full | 9.47 | 20.84 | 19.20 | 18.00 | 26.77 | 27.05 | 14.77 |
| OmniGen2 | 10.67 | 22.51 | 22.89 | 18.63 | 28.00 | 22.61 | 16.24 |
| FLUX.1 Dev | 12.35 | 20.09 | 19.86 | 20.63 | 25.25 | 27.00 | 16.51 |
| FLUX.1 Kontext | 17.22 | 24.64 | 21.42 | 24.06 | 30.97 | 29.16 | 20.36 |
| Ovis-U1 | 24.75 | 16.08 | 19.45 | 21.23 | 26.03 | 12.70 | 22.83 |
| Qwen-Image | 32.23 | 48.05 | 46.98 | 48.90 | 53.51 | 73.65 | 41.03 |
| Ours | 20.91 | 33.45 | 41.70 | 30.66 | 41.46 | 32.26 | 28.80 |
StructEditBench (charts only) — reporting Accuracy (%) & PSNR. Click any column to sort. Best Performance Second Best
| Model | Category | Color | Num | Auxiliary | Add&Del | Overall | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc ↑ | PSNR ↑ | Acc ↑ | PSNR ↑ | Acc ↑ | PSNR ↑ | Acc ↑ | PSNR ↑ | Acc ↑ | PSNR ↑ | Acc ↑ | PSNR ↑ | |
| GPT-Image | 40.62 | 9.85 | 54.57 | 13.91 | 33.12 | 13.48 | 64.03 | 13.48 | 38.02 | 12.73 | 45.82 | 12.56 |
| Nano Banana | 39.75 | 10.33 | 54.34 | 17.59 | 35.64 | 16.56 | 67.40 | 17.39 | 36.77 | 13.88 | 46.42 | 14.93 |
| Seedream 4.0 | 38.13 | 9.67 | 61.84 | 21.77 | 36.00 | 19.22 | 65.92 | 19.46 | 36.04 | 14.28 | 46.83 | 16.54 |
| UniWorld-V1 | 5.98 | 7.60 | 8.19 | 8.29 | 2.58 | 7.57 | 10.24 | 8.62 | 2.81 | 7.35 | 5.99 | 7.87 |
| DiMOO | 11.20 | 9.82 | 15.31 | 16.97 | 17.39 | 17.30 | 21.57 | 17.59 | 18.57 | 14.46 | 16.52 | 14.98 |
| OmniGen2 | 17.30 | 8.61 | 28.84 | 11.78 | 15.48 | 14.03 | 22.42 | 16.59 | 10.54 | 12.11 | 18.55 | 12.44 |
| Ovis-U1 | 18.15 | 9.57 | 30.68 | 15.38 | 20.79 | 15.13 | 25.49 | 14.25 | 17.21 | 13.11 | 21.94 | 13.30 |
| Hidream-E1.1 | 22.69 | 9.29 | 39.86 | 14.07 | 21.49 | 15.04 | 32.65 | 14.34 | 18.05 | 12.71 | 26.36 | 12.91 |
| Bagel | 25.69 | 9.08 | 38.20 | 20.46 | 26.30 | 20.29 | 30.00 | 21.24 | 17.79 | 14.93 | 27.11 | 16.82 |
| Step1X-Edit | 21.96 | 10.40 | 36.51 | 19.75 | 25.46 | 20.22 | 34.40 | 19.46 | 24.92 | 15.11 | 28.05 | 16.68 |
| Bagel-Think | 24.55 | 9.00 | 45.46 | 19.35 | 25.60 | 20.14 | 34.54 | 20.62 | 18.69 | 14.58 | 28.98 | 16.38 |
| Qwen-Edit | 23.53 | 9.52 | 41.80 | 13.63 | 22.90 | 13.69 | 42.39 | 13.07 | 23.27 | 12.46 | 30.17 | 12.33 |
| FLUX.1 Kontext | 24.67 | 10.14 | 44.56 | 16.53 | 29.24 | 16.74 | 44.02 | 16.79 | 23.06 | 13.95 | 32.29 | 14.61 |
| Ours | 50.81 | 10.40 | 64.10 | 18.16 | 33.45 | 17.04 | 66.34 | 17.90 | 38.10 | 14.37 | 50.58 | 15.33 |
Structured Image Dataset
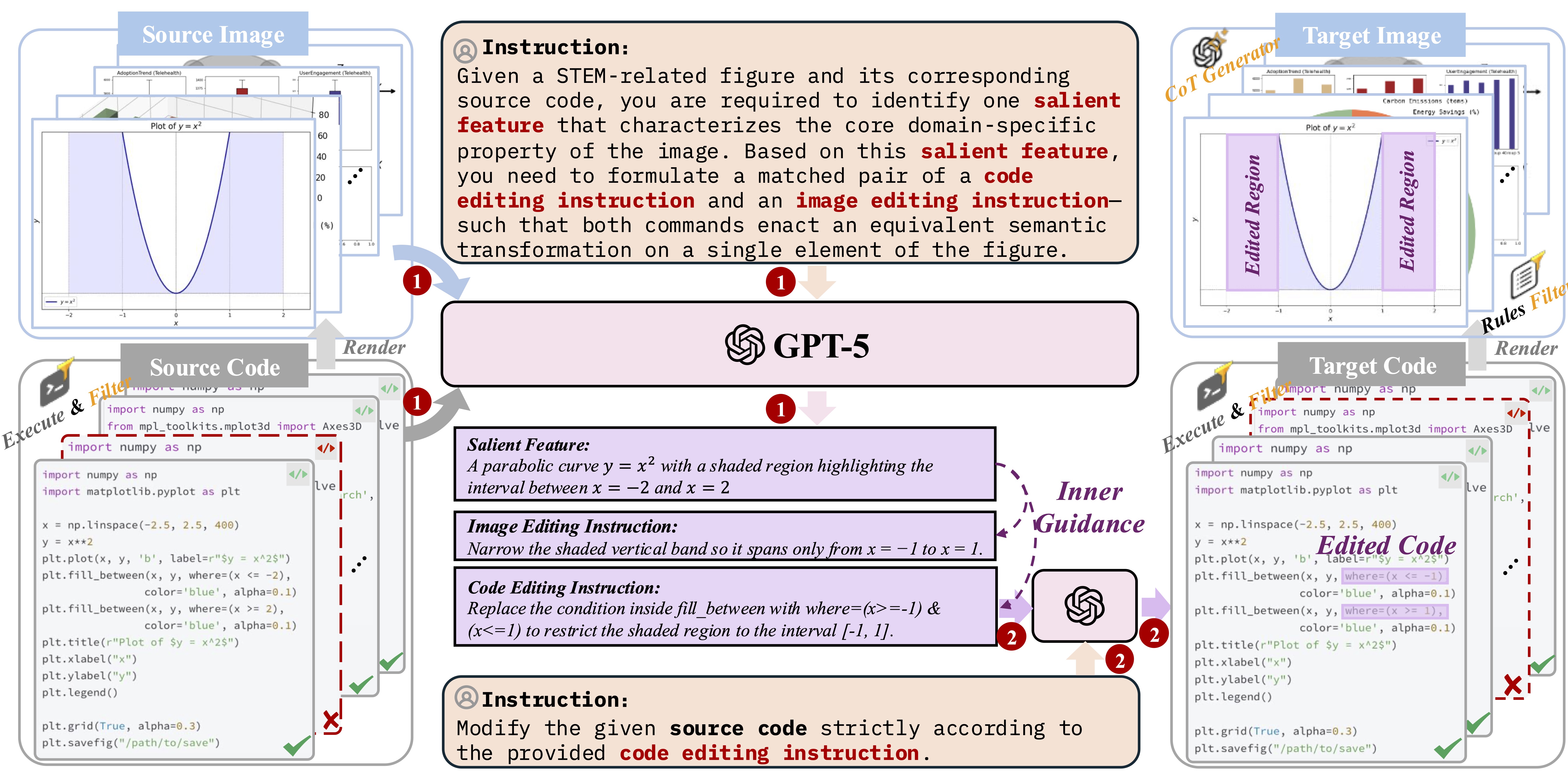
We release a large-scale Structured Image Dataset tailored for generation and editing of charts, diagrams, math figures, and more. Starting from ~2M executable programs (Python, LaTeX) across diverse categories, we render valid source images, use GPT-5 to extract salient visual features, and jointly produce aligned image-editing and code-editing instructions. GPT-5 then applies code edits to synthesize target programs and images, yielding strictly aligned source-target pairs. A comprehensive post-processing pipeline removes invalid, low-difference, and low-information samples, resulting in 1.3M high-quality examples. Each example includes source/target images, a dense caption, an image-editing instruction, and a three-step reasoning trajectory to support precise, fact-grounded structured visual generation and editing.
Benchmark Construction
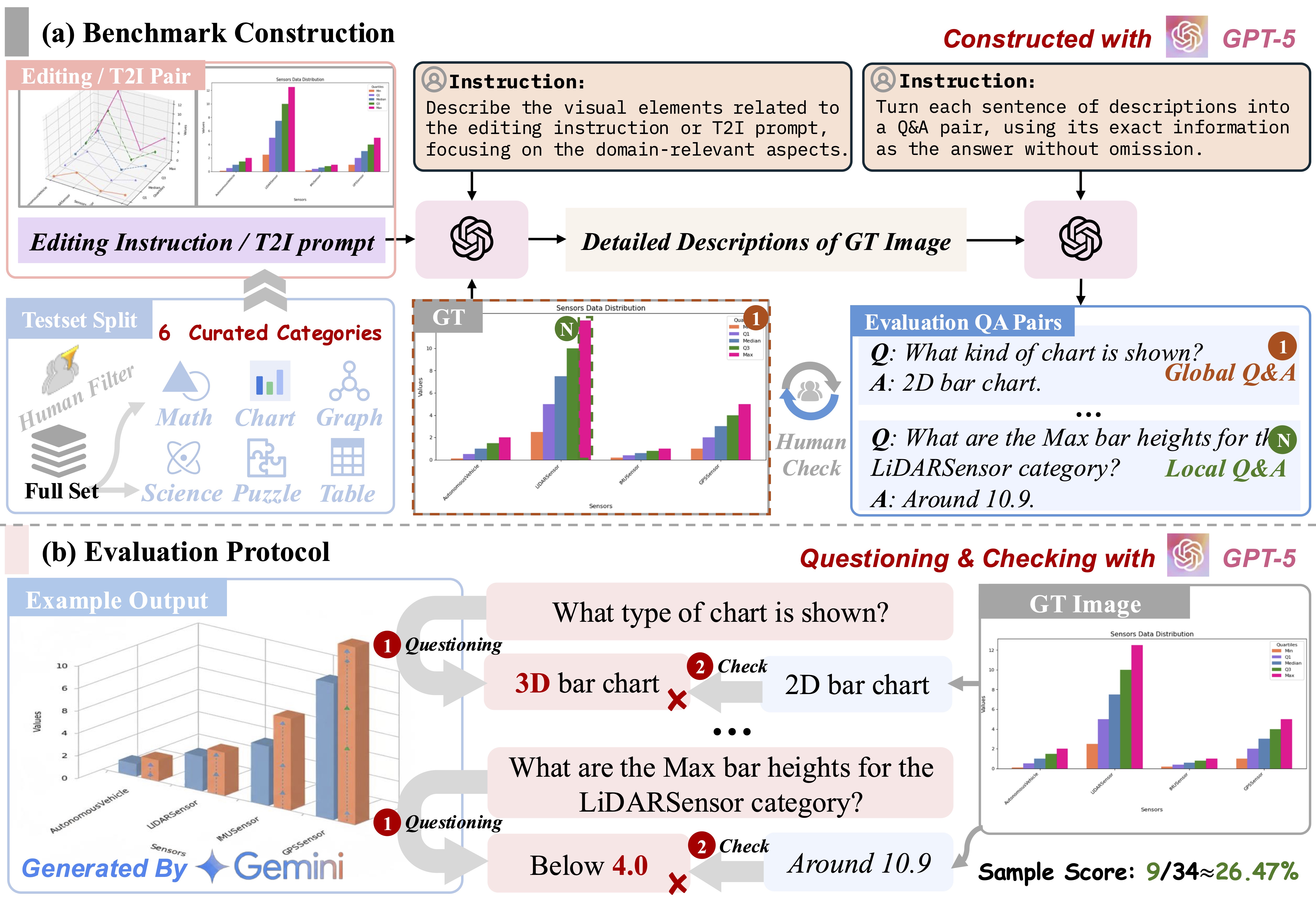
StructBench is a curated benchmark for structured visual generation and editing, spanning Math, Graph, Chart, Puzzle, and Table domains. We select diverse, high-quality items from our code-rendered dataset via clustering, stratified sampling, and dual GPT-5/human review. For each item, GPT-5 produces detailed descriptions that are decomposed into atomic Q&A pairs covering fine-grained attributes and relations. Evaluation uses StructScore, a controlled multi-turn VLM protocol with open-ended answers compared against concise ground truths. Through human audits and iterative Q&A refinement, metric reliability on ground-truth images improves from ~80% to >95%. The final benchmark includes 1,714 items with 32,031 and 37,941 Q&A pairs for editing and generation respectively.
Model Training
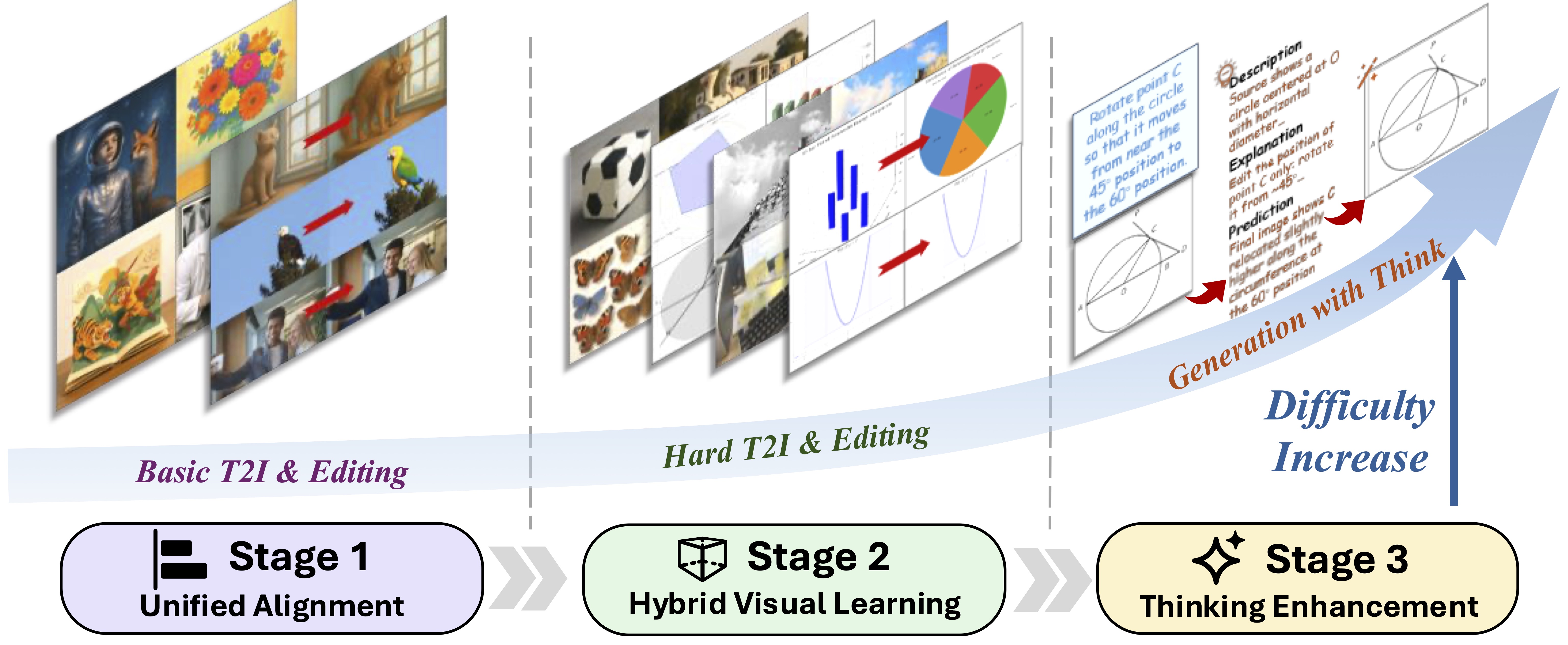
We build on FLUX.1 Kontext, adapting its unified diffusion transformer for structured image generation and editing. Text is encoded with T5 (we discard CLIP), while both input and target images are encoded by a VAE; these tokens are concatenated and processed with joint attention. To strengthen high-level semantic understanding crucial for structured visuals, we add a lightweight MLP connector that aligns Qwen-VL multimodal features with the backbone, offering stable optimization and low overhead. Training proceeds in three stages: (1) Unified Alignment—freeze the backbone and train only the connector using simple data, suppressing T5 to avoid shortcutting; (2) Hybrid Visual Learning—jointly fine-tune on structured and general datasets with a mask-based loss that downweights backgrounds and unchanged regions; and (3) Thinking Enhancement—inject chain-of-thought reasoning via Qwen-VL and enable inference-time reasoning, where a VLM analyzes the input and guides the generator for complex, semantically grounded edits.
Citation
@article{zhuo2025structbench,
title={Factuality Matters: When Image Generation and Editing Meet Structured Visuals},
author={Zhuo, Le and Han, Songhao and Pu, Yuandong and Qiu, Boxiang and Paul, Sayak and Liao, Yue and Liu, Yihao and Shao, Jie and Chen, Xi and Liu, Si and Li, Hongsheng},
journal={arXiv preprint arXiv:2510.05091},
year={2025}
}
Acknowledgements
We thank Ximing Xing for providing us with the source code of the web page to help us build the project home page.